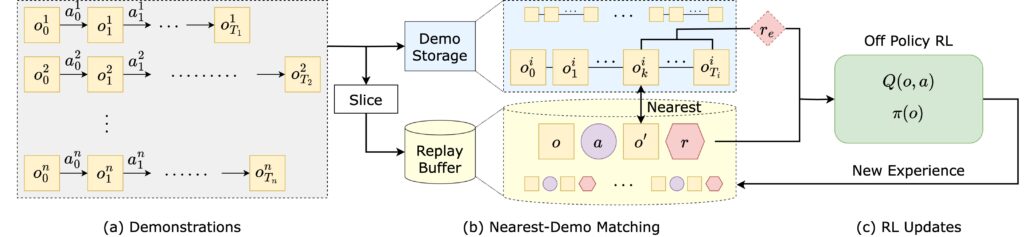
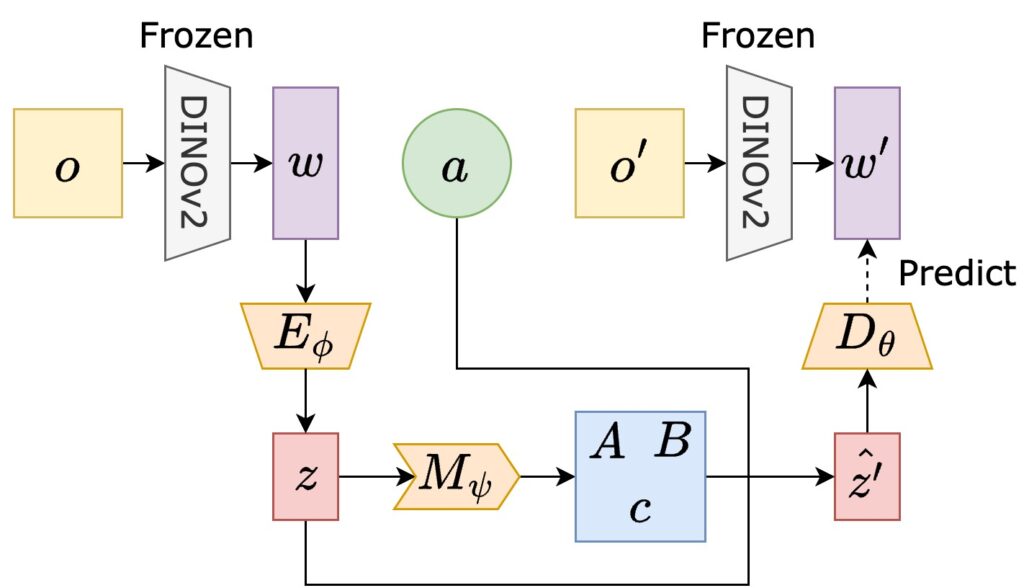
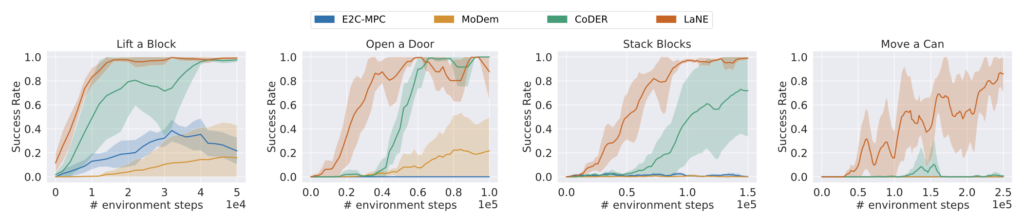
LaNE is a data-efficient reinforcement learning (RL) method to solve sparse-reward tasks from image observations. First, LaNE builds on the pre-trained DINOv2 feature extractor to learn an embedding space for forward prediction. Next, it rewards the agent for exploring near the demonstrations, quantified by quadratic control costs in the embedding space. Our method achieves state-of-the-art sample efficiency in Robosuite simulation and enables under-an-hour RL training from scratch on a Franka Panda robot, using only a few demonstrations.